topic和partition
topic只是一个逻辑概念,代表了一类消息,也可以认为是消息被发送到的地方。通常我们可以使用topic来区分实际业务,比如业务A使用一个topic,业务B使用另外一个topic。Kafka中的topic通常都会被多个消费者订阅,因此出于性能的考量,Kafka并不是topicmessage的两级结构,而是采用了topicpartitionmessage的三级结构来分散负载。从本质上说,每个Kafkatopic都由若干个partition组成。
这张来自Kafka官网的topic和partition关系图非常清楚地表明了它们二者之间的关系:topic是由多个partition组成的,而Kafka的partition是不可修改的有序消息序列,也可以说是有序的消息日志。每个partition有自己专属的partition号,通常是从0开始的。用户对partition唯一能做的操作就是在消息序列的尾部追加写入消息。partition上的每条消息都会被分配一个唯一的序列号——按照Kafka的术语来讲,该序列号被称为位移(offset)。该位移值是从0开始顺序递增的整数。位移信息可以唯一定位到某partition下的一条消息。
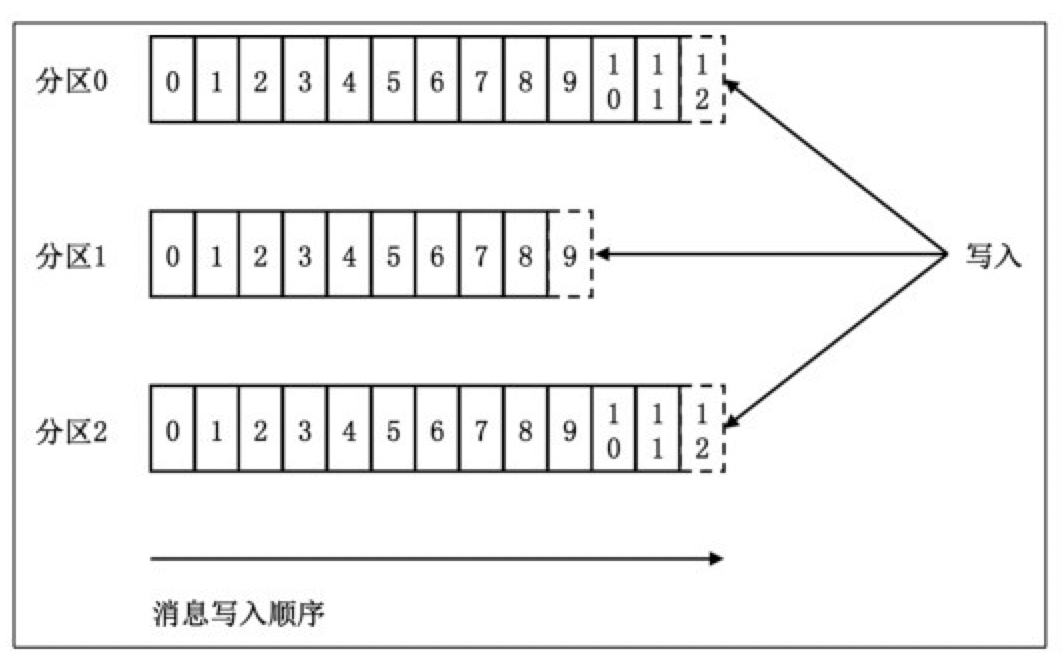
值得一提的是,Kafka的partition实际上并没有太多的业务含义,它的引入就是单纯地为了提升系统的吞吐量,因此在创建Kafkatopic的时候可以根据集群实际配置设置具体的partition数,实现整体性能的最大化。
offset
topic partition下的每条消息都被分配一个位移值。实际上,Kafka消费者端也有位移(offset)的概念,但一定要注意这两个offset属于不同的概念,如图所示。
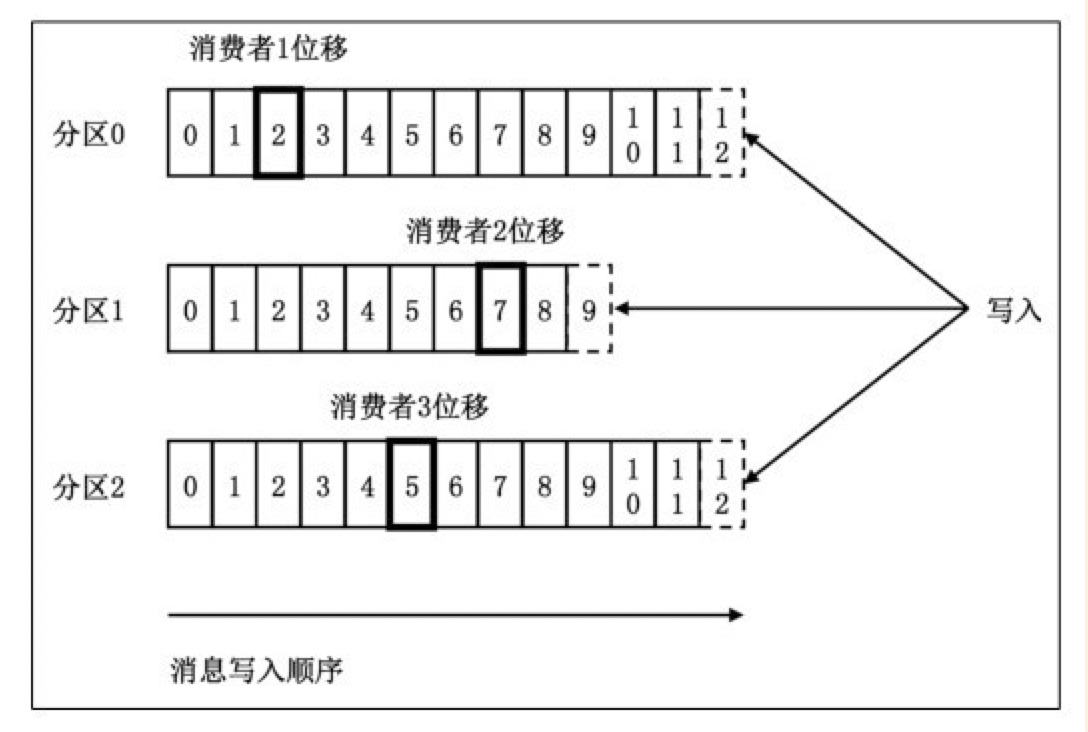
显然,每条消息在某个partition的位移是固定的,但消费该partition的消费者的位移会随着消费进度不断前移,但终究不可能超过该分区最新一条消息的位移。因此以后在讨论位移的问题时一定要给出清晰的上下文环境,这样才能明确要讨论的是哪个位移。
综合之前说的topic、partition和offset,我们可以断言Kafka中的一条消息其实就是一个<topic,partition,offset>三元组(tuple),通过该元组值我们可以在Kafka集群中找到唯一对应的那条消息。
replica
既然我们已知partition是有序消息日志,那么一定不能只保存这一份日志,否则一旦保存partition的Kafka服务器挂掉了,其上保存的消息也就都丢失了。分布式系统必然要实现高可靠性,而目前实现的主要途径还是依靠冗余机制——简单地说,就是备份多份日志。这些备份日志在Kafka中被称为副本(replica),它们存在的唯一目的就是防止数据丢失,这一点一定要记住!
副本分为两类:领导者副本(leaderreplica)和追随者副本(followerreplica)。followerreplica是不能提供服务给客户端的,也就是说不负责响应客户端发来的消息写入和消息消费请求。它只是被动地向领导者副本(leaderreplica)获取数据,而一旦leaderreplica所在的broker宕机,Kafka会从剩余的replica中选举出新的leader继续提供服务。下面我们就来看看什么是leader和follower。
leader和follower
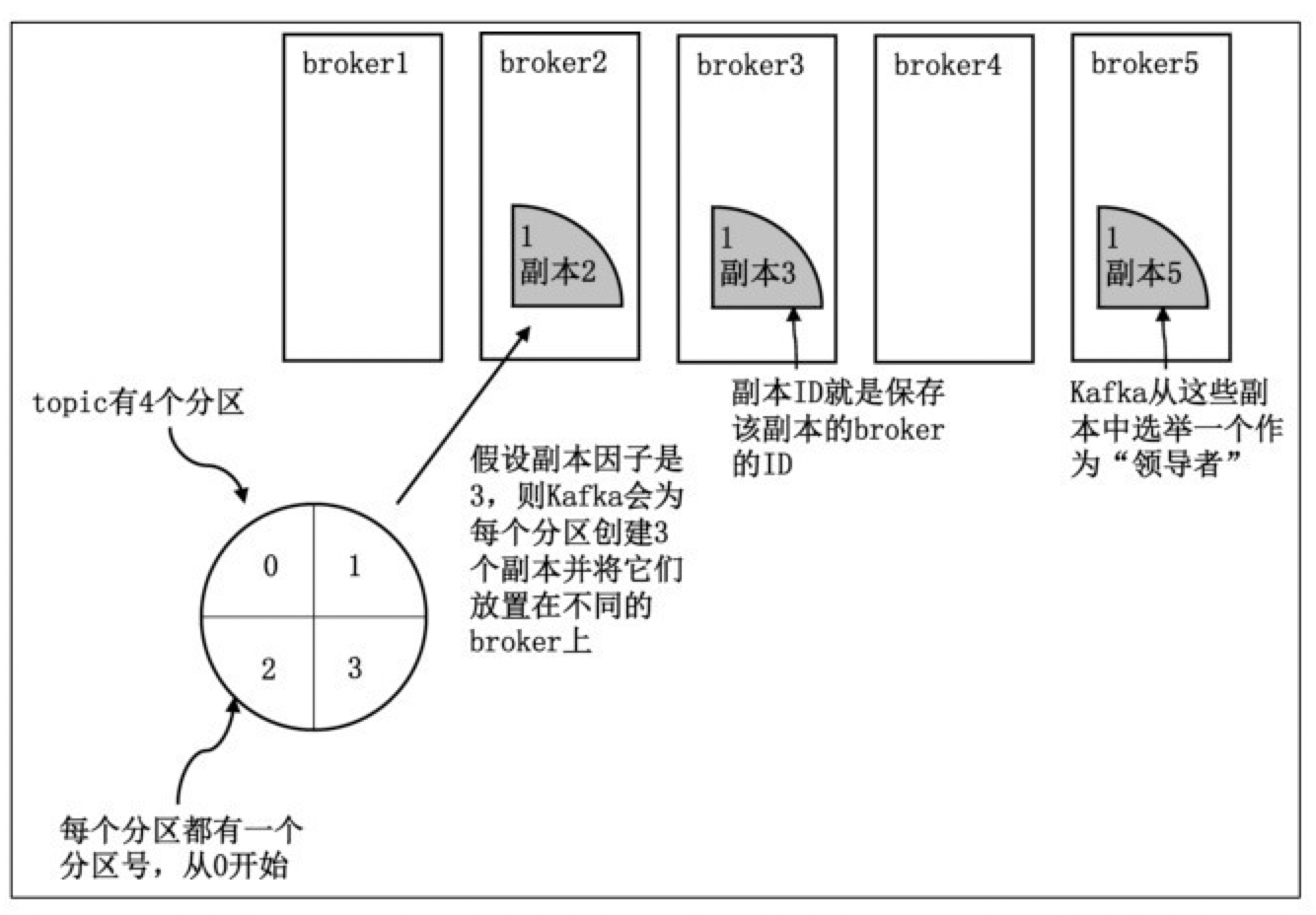
如前所述,Kafka的replica分为两个角色:领导者(leader)和追随者(follower)。如今这种角色设定几乎完全取代了过去的主备的提法(MasterSlave)。和传统主备系统(比如MySQL)不同的是,在这类leaderfollower系统中通常只有leader对外提供服务,follower只是被动地追随leader的状态,保持与leader的同步。follower存在的唯一价值就是充当leader的候补:一旦leader挂掉立即就会有一个追随者被选举成为新的leader接替它的工作。Kafka就是这样的设计,如图所示。
Kafka保证同一个partition的多个replica一定不会分配在同一台broker上。毕竟如果同一个broker上有同一个partition的多个replica,那么将无法实现备份冗余的效果。
ISR
ISR的全称是in-sync replica,翻译过来就是与leaderreplica保持同步的replica集合。这是一个特别重要的概念。前面讲了很多关于Kafka的副本机制,比如一个partition可以配置N个replica,那么这是否就意味着该partition可以容忍N1个replica失效而不丢失数据呢?答案是“否”!
Kafka为partition动态维护一个replica集合。该集合中的所有replica保存的消息日志都与leaderreplica保持同步状态。只有这个集合中的replica才能被选举为leader,也只有该集合中所有replica都接收到了同一条消息,Kafka才会将该消息置于“已提交”状态,即认为这条消息发送成功。回到刚才的问题,Kafka承诺只要这个集合中至少存在一个replica,那些“已提交”状态的消息就不会丢失——记住这句话的两个关键点:①ISR中至少存在一个“活着的”replica;②“已提交”消息。有些Kafka用户经常抱怨:我向Kafka发送消息失败,然后造成数据丢失。其实这是混淆了Kafka的消息交付承诺(messagedeliverysemantic):Kafka对于没有提交成功的消息不做任何交付保证,它只保证在ISR存活的情况下“已提交”的消息不会丢失。
正常情况下,partition的所有replica(含leaderreplica)都应该与leaderreplica保持同步,即所有replica都在ISR中。因为各种各样的原因,一小部分replica开始落后于leaderreplica的进度。当滞后到一定程度时,Kafka会将这些replica“踢”出ISR。相反地,当这些replica重新“追上”了leader的进度时,那么Kafka会将它们加回到ISR中。这一切都是自动维护的,不需要用户进行人工干预,因而在保证了消息交付语义的同时还简化了用户的操作成本。